34. GPUを使用したサンプルワークフロー¶
ワークフローデザイナで、GPU(CUDA)を使うプログラムを動かすワークフローについて記述する。 動かしているソルバーは、nVidiaのCUDAサンプルに付録している行列積計算のプログラム(matrixMul)である。
34.1. 理論¶
行列の積を求める計算は、要素ごとに乗算と加算を繰り返し、O(N^3)の計算量になり、 メモリ使用量は、O(N^2)のオーダーで消費し、全要素にアクセスが必要な事から、 計算量とメモリバンド幅を同時に使うため、ベンチマークソフトとして使われることがしばしばある。 今回のサンプルワークフローとして、行列積計算プログラムを使用することにした。
GPUボードは、Quadro K620を想定していて、行列サイズは、4800×4800の固定値でコンパイルしたものを使用している。
GPUでの計算時間は約2秒、検算のためのCPU計算時間は、約30分を想定している。
34.2. GPGPU_testワークフローの利用¶
GPGPU_matmal と言うツールをワークフローデザイナのデザイン画面にドラッグ&ドロップする。
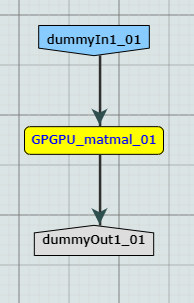
図 792 GPGPUテストワークフロー¶
他のツールとの連携を想定していないので、単体ツールのワークフローとなる。
34.4. 出力¶
ファイルとしての出力は行わない。
標準出力に以下のような出力を行う。
[Matrix Multiply Using CUDA] - Starting...
GPU Device 0: "Quadro K620" with compute capability 5.0
MatrixA(4800,4800), MatrixB(4800,4800)
Computing result using CUDA Kernel...
done
Performance= 35.87 GFlop/s, Time= 6166.407 msec, Size= 221184000000 Ops, WorkgroupSize= 1024 threads/block
Checking computed result for correctness: Result = PASS
NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.
done.
34.5. GPU使うツールを複数個Torque実行した場合¶
GPGPUテストワークフローのツールは、開発環境の以下のディレクトリに配置している。
/home/misystem/assets/modules/gpgpu_test
このディレクトリ内の wf_run.sh がワークフローからの入力を受け付けるシェルスクリプトになっている。
matrixMul がnVidiaのサンプルから、行列サイズを変更した CUDA 実行ファイルだ。
Torque実行するスクリプトは、pbs_run.sh になっていて、設定は、1ノード1プロセス動作を指定している。 キューは、ex_queue を指定して、ワークフローデザイナと同一のキューを指定している。 複数回 qsub するために、multi_run.sh を作成して、pbs_run.sh を実行するようにしている。 デフォルトでは、0から10までの11個のジョブがキューに登録される。
multi_run.sh を使用し、GPUジョブを複数投入したときのqstatの様子を、 図 793 に示す。
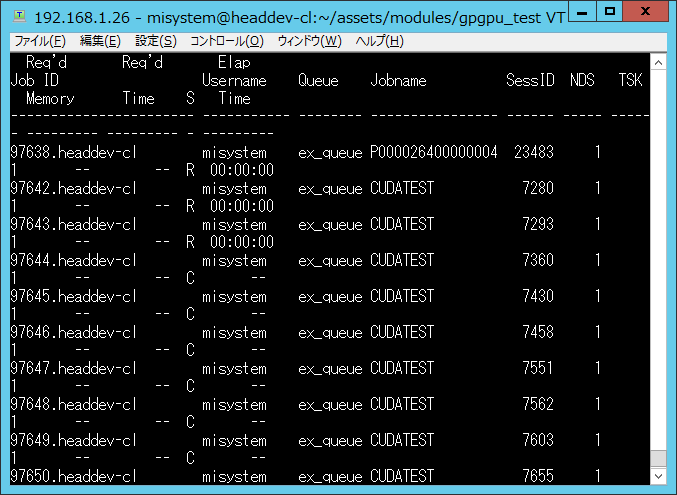
図 793 ジョブを11個投入したときのqstat(一部)¶
図 793 に示したとおり、3番目以降の pbs_run.sh がステータスCの終了になっている。
3番目の pbs_run.sh に残されているエラーメッセージを以下に示す。
MatrixA(4800,4800), MatrixB(4800,4800)
cudaMalloc d_C returned error out of memory (code 2), line(181)
done.
メモリがGPU上に確保できなかったというエラーメッセージが記されている。 その時のGPUの状態を、nvidia-smiコマンドを使用して調査した結果を、 図 794 に示す。
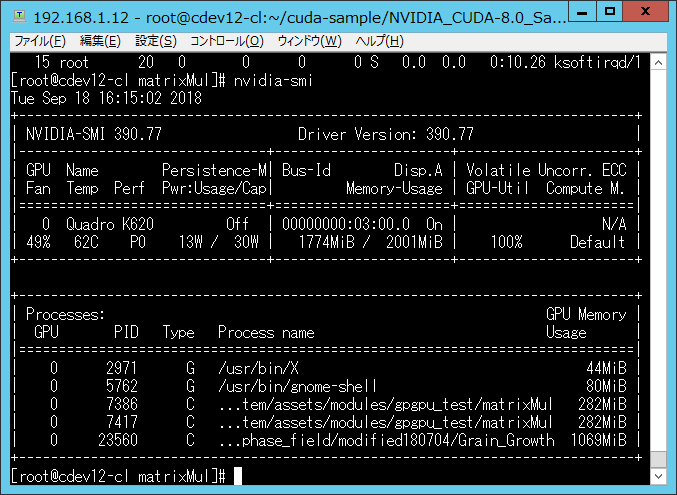
図 794 nVidia SMIコマンドでGPUの状態を確認した画面¶
既に、2000MB中1700MB以上のVRAMが割り当てられていて、追加で、300MBのVRAMを割り当てられる状況にないことが分かる。
この時の計算ノードのTOPで確認した実行中のプロセスを、 図 795 から 図 797 に示す。
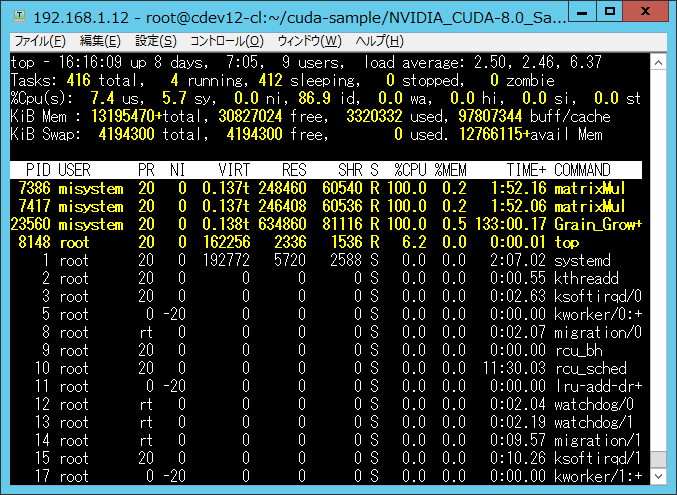
図 795 cdev12のプロセス状況¶
メモリの使用量の都合で割り当てられた2プロセスの実行を確認できる。
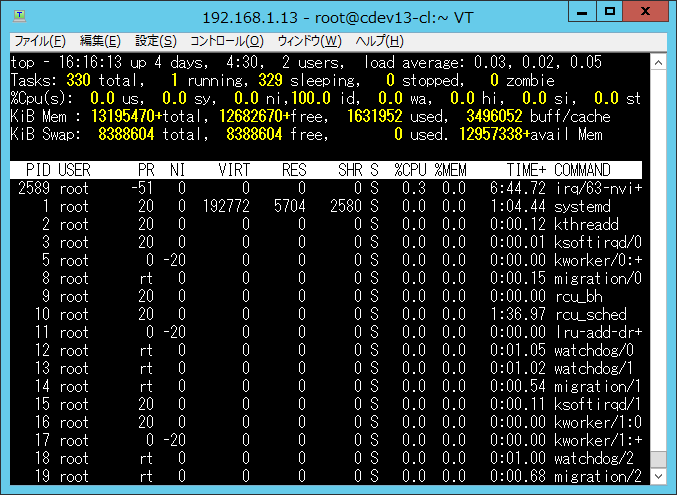
図 796 cdev13のプロセス状況¶
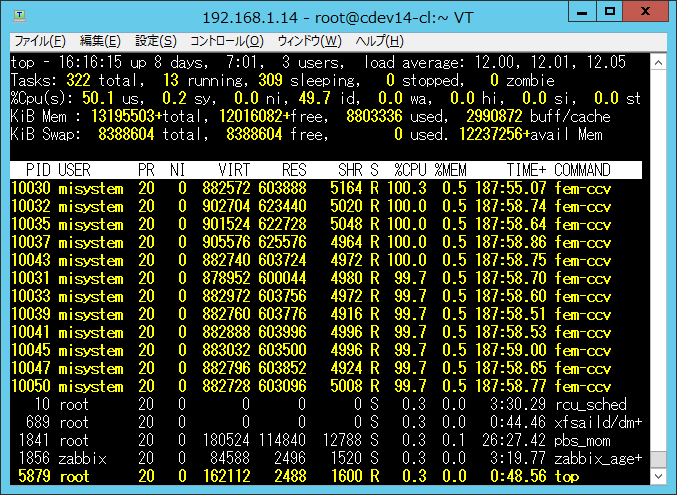
図 797 cdev14のプロセス状況¶
cdev13、cdev14のTOPには、「matrixMul」の文字が現れることはなかった。 なので、Torqueはcdev12にすべての pbs_run.sh を割り当て、GPUのメモリが確保できなかった matrixMulプロセスが、 順次終了していき、11個のジョブがcdev12内で処理されたと考えられる。
34.6. まとめ¶
ワークフローデザイナ上からCUDAを使用するアプリケーションを動作させることが可能だと確認ができた。
一方で、GPUを複数のツールやワークフローで使用する場合、Torque側でGPUのリソース状況を知ることができないため、 全部同一ノードにジョブを割り当ててしまうため、GPUを使用した計算に失敗することが分かった。
なので、GPUを使うワークフローは、GPUの状態をモニターできるTorqueを使うか、利用者の話し合いでGPUを使用するジョブの投入を行う必要がある。
34.7. 課題¶
現在のTorqueの設定では、1つのノードにすべてのGPUソフトを割り振ってしまうため、 デザイナを使用して多くのGPUを使用するワークフローを、並列で実行することができない。
CPUの検算を高速化するには、OpenMPなどで、CPUコードも並列化を行う必要がある。
